AWS Breaking Glass Accounts : Stratégie d'Urgence pour l'Entreprise
- Published on
- Authors

- Name
- Sylvain BRUAS
- @sylvain_bruas

Vous rappelez-vous la dernière fois que vous avez réellement écouté les consignes de sécurité vous indiquant les sorties de secours lors d'un vol ? Vous rappelez-vous la dernière fois que vous avez cherché les vitres dédiées aux évacuations en prenant le train ?
Nous avons tendance à nous croire en sécurité dès que les actions de sécurité deviennent des routines. Il en va de même quand nous avons mis en place les fondations de notre landing zone.
Posez-vous les questions suivantes et surtout êtes-vous certain de pouvoir y répondre ?
- Que se passe-t-il si AWS Identity Manager n'est plus capable de me donner accès à mes comptes ?
- Que se passe-t-il si mon référentiel d'authentification (Microsoft Active Directory, Okta...) ne fonctionne plus ou est mal configuré ?
- Que se passe-t-il si mes rôles projets sont modifiés et que je ne peux plus accéder à mes comptes projets ?
Pour se prémunir de ce type de problème, il est nécessaire de préparer un plan B ou un parachute de secours. Cette solution, ce sont les comptes de secours (Breaking Glass).
Nous allons voir comment mettre tout cela en place, mais aussi réfléchir à comment ne pas compromettre la sécurité et la gouvernance de votre landing zone.
Qu'est-ce qu'un compte AWS Breaking Glass ?
Un compte AWS Breaking Glass est un compte d'urgence hautement privilégié, conçu pour permettre l'accès aux ressources cloud lors de circonstances exceptionnelles où les mécanismes d'accès normaux sont compromis ou indisponibles.
Le terme "Breaking Glass" fait référence aux boîtiers d'urgence en verre qu'il faut briser pour accéder aux équipements de sécurité incendie - une illustration parfaite de leur fonction.
Dans ce compte AWS, nous allons créer des utilisateurs AWS Identity and Access Management (IAM) nominatifs. Ces comptes sont caractérisés par des privilèges administratifs étendus, une surveillance renforcée et des procédures d'activation strictement contrôlées. Ils constituent une bouée de sauvetage pour les organisations lorsque les systèmes de gouvernance habituels deviennent inopérants.
Pourquoi un compte pour l'accès Breaking Glass ?
Tout simplement car les ressources que nous allons créer seront très fortement contrôlées, et nous voulons réduire au strict minimum les droits ouverts sur ce compte.
Nous suivons le principe KISS (https://fr.wikipedia.org/wiki/Principe_KISS), en mettant en œuvre que ce qui est nécessaire. Nous allons ainsi pouvoir mettre en place des SCPs très restrictives sur ce compte, en partant d'un "deny all", tout en gardant une complexité contrôlée.
Le compte payeur ne serait pas une bonne idée pour faire cette implémentation car ce compte n'est pas affecté par les SCPs (https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps.html).
Extrait :
Les SCPs n'affectent pas les utilisateurs ni les rôles dans le compte de gestion. Elles affectent uniquement les comptes membres de votre organisation. Cela signifie également que les SCPs s'appliquent aux comptes de membres désignés comme administrateurs délégués.
Quels services allons-nous utiliser ?
Évidemment, le premier service utilisé sera IAM. Il servira à faire les switch roles vers les autres comptes. Pour surveiller les activités sur ce compte, nous allons utiliser AWS CloudTrail et Amazon EventBridge qui permettront de transmettre vers Amazon Simple Notification Service (SNS) les alertes sur les événements que nous aurons choisi d'observer.
Il peut être également intéressant de mettre ce compte comme administrateur délégué pour plusieurs services, comme AWS Health ou Amazon CloudWatch.
Nous allons renforcer tout cela avec des SCPs pour réduire les services disponibles sur ce compte.
Sécurisation physique
Pour renforcer la sécurité de ces comptes, je vous recommande d'utiliser des MFA physiques pour ces utilisateurs de secours. L'idéal étant de stocker dans un coffre-fort ces objets, pour interdire toute utilisation sans qu'un responsable qui a accès au coffre ne puisse donner la clé MFA.
Une autre solution est de laisser le MFA virtuel à une autre équipe comme l'équipe sécurité par exemple. Il faut néanmoins vérifier qu'une présence 24/7 est prévue au sein de cette équipe.
Dans ce scénario, si un utilisateur doit se connecter, il contactera l'équipe réseau pour récupérer le MFA et l'installer sur son téléphone. À la fin de l'opération, il recontactera en visioconférence l'équipe sécurité pour détruire en direct le MFA sur son téléphone.
Architecture
Nous allons travailler dans 3 comptes
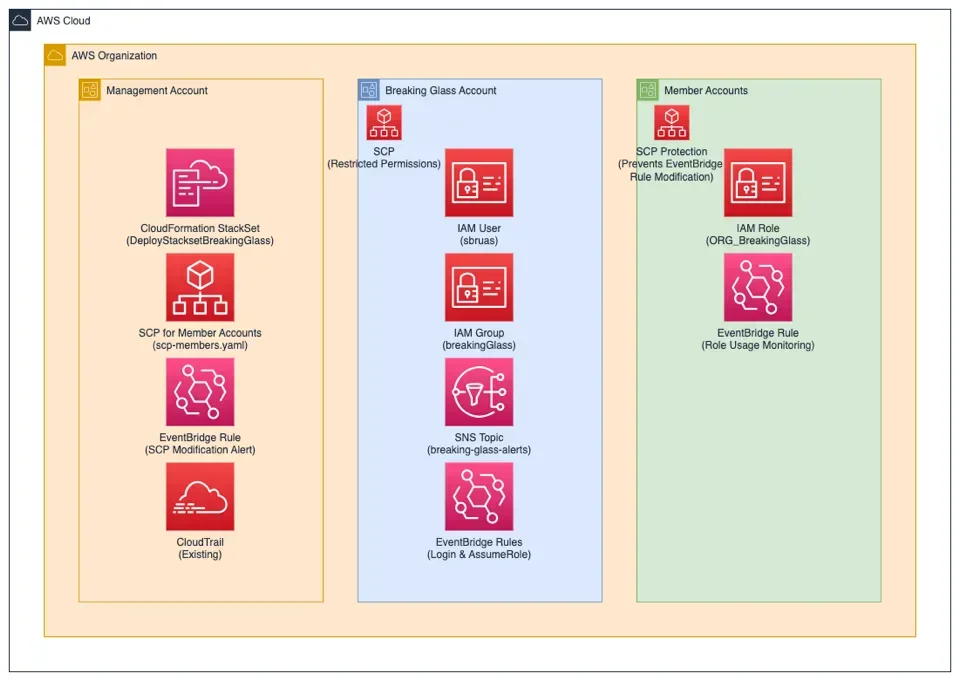
Compte payeur
Dans ce compte, nous allons déployer les SCPs qui auront 2 rôles.
Le premier est de limiter au maximum ce que l'on peut faire dans le compte breaking glass, ce qui se résume à utiliser un rôle et à observer les événements sur le compte.
La seconde SCP va servir à protéger les règles EventBridge dans les comptes membres. On s'assure ainsi que l'on ne perde pas les alertes.
Nous allons déployer également des règles EventBridge au niveau du compte payeur pour détecter toute modification des StackSets liées au Breaking Glass.
Compte Breaking Glass
Nous allons déployer dans un premier temps les utilisateurs et l'observabilité. Quand ces premiers éléments seront en place, nous mettrons en place la SCP qui ne nous permettra plus de faire de modifications sur ce compte.
Si à terme nous voulons par exemple ajouter un utilisateur, nous devrons détacher la SCP (ce qui déclenchera une alerte), faire la modification puis réattacher la SCP.
Nous permettons aux utilisateurs de modifier leur mot de passe, c'est l'une des rares actions de modifications que nous laissons actives sur ce compte.
Comptes Membres
Dans ces comptes, nous allons déployer un rôle avec des droits administrateur exclusivement à destination des utilisateurs du compte Breaking Glass, des règles EventBridge pour superviser l'utilisation de ce rôle. Tout cela étant protégé par la SCP.
Étapes de mise en œuvre
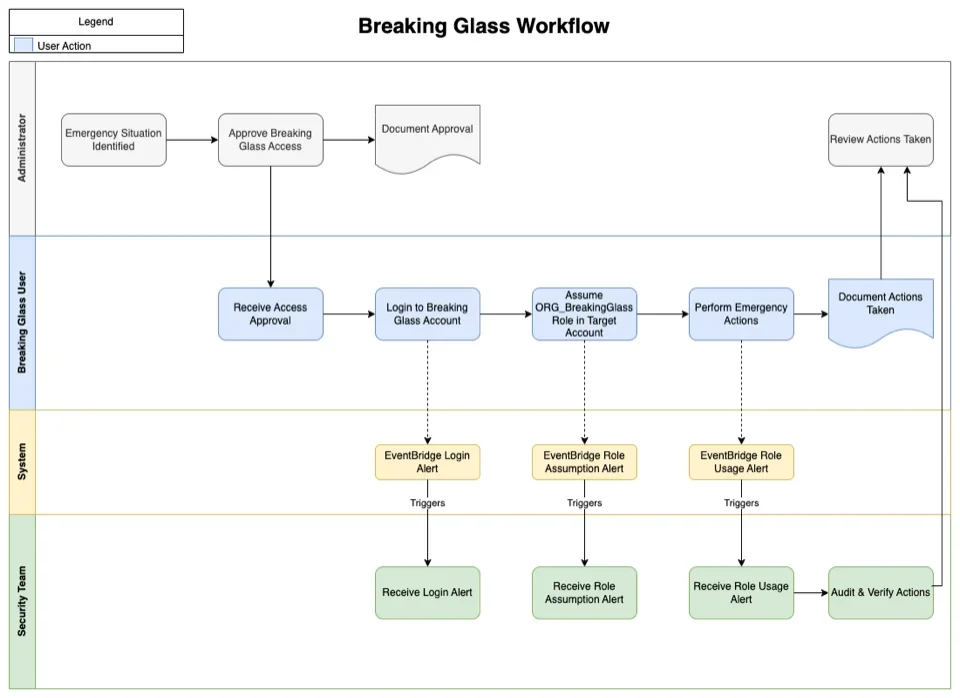
Entretien et conformité
Il est nécessaire de définir exhaustivement et mettre à jour régulièrement la procédure de déclenchement du Breaking Glass. Elle doit inclure les procédures d'activation, les contacts d'urgence, les escalades hiérarchiques et les post-mortems des utilisations passées. Cette documentation doit être stockée de manière redondante et accessible même en cas de défaillance des systèmes principaux.
Il est tout aussi important de faire des revues régulières, pour vérifier que tout fonctionne, qu'il n'y ait pas de drift au niveau de AWS CloudFormation qui empêcherait par exemple le déploiement du rôle d'administration dans tous les comptes. Les comptes AWS Break Glass doivent faire l'objet de tests réguliers pour garantir leur fonctionnement en cas d'urgence réelle. Ces tests doivent simuler différents scénarios de défaillance et inclure l'ensemble des parties prenantes.
Une gestion fine des utilisateurs est aussi nécessaire. Si l'un d'eux vient à quitter la société, il faut immédiatement désactiver son compte et désigner une personne de confiance pour reprendre sa fonction.
L'activation d'un compte AWS Break Glass doit suivre un processus rigoureux et documenté. Ce processus commence généralement par une procédure d'escalade impliquant plusieurs niveaux hiérarchiques.
La procédure d'activation doit inclure la notification automatique des équipes de sécurité, de la direction technique et des responsables de la gouvernance. Chaque activation doit être documentée avec une justification détaillée, un horodatage précis et l'identification claire du personnel impliqué.
À la fin de la procédure d'activation, un résumé des actions doit être créé pour identifier les actions à mener sur le long terme, les correctifs à implémenter selon les normes de la société (Infrastructure as Code), ainsi que tous les commentaires permettant d'éviter la réactivation de ce plan de secours. Ce document doit être partagé avec toutes les parties prenantes.
Les comptes AWS Breaking Glass doivent s'aligner avec les frameworks de sécurité utilisés au sein de l'entreprise comme NIST, PCI DSS, HIPAA ou ISO 27001. Il sera donc nécessaire de documenter précisément les procédures, les contrôles d'accès et les mécanismes d'audit.
L'écosystème AWS évoluant rapidement, les stratégies de Breaking Glass doivent être régulièrement réévaluées. L'intégration de nouveaux services AWS, l'évolution des menaces de sécurité et les changements organisationnels nécessitent des adaptations continues.
Observabilité et Auditabilité
Le monitoring des AWS Breaking Glass Accounts représente un défi. Chaque action effectuée via ces comptes doit être tracée et enregistrée.
Pour l'auditabilité et les actions lancées, nous allons nous reposer sur CloudTrail. Nous partons du principe qu'il est implémenté au niveau de l'organisation, sur tous les comptes et toutes les régions. Nous considérons que les événements sont sauvegardés sur Amazon Simple Storage Service (S3) pour la traçabilité sur le long terme, et que les événements principaux sont audités en quasi temps réel par un SOC (Security Operations Center).
Côté Observabilité, nous utilisons EventBridge comme cité précédemment, ce qui permet une grande réactivité. Ce service sera appuyé par des SCPs pour sécuriser la chaîne d'alerte.
Aspects FinOps
Ce compte reste généralement dormant mais doit maintenir des ressources critiques disponibles en permanence. Les coûts restent assez faibles, l'utilisation étant quasi nulle, les FinOps pourraient légitimement vouloir désactiver certaines ressources considérées comme inutiles. Ce compte doit rester hors du processus de nettoyage FinOps, et ne doit être suivi que sur le plan financier, via Cost Anomaly Detection et des alertes Budget par exemple.
Ce qu'il faut retenir
Les AWS Breaking Glass Accounts représentent un élément essentiel de toute stratégie de sécurité cloud mature. Leur implémentation nécessite une approche globale intégrant les aspects techniques, organisationnels et financiers.
La mise en œuvre peut sembler complexe, mais elle permettra une plus grande réactivité en cas d'incidents graves.
L'investissement dans une stratégie de "Break Glass" bien conçue et régulièrement testée peut faire la différence entre une récupération rapide et une interruption d'activité prolongée lors d'incidents critiques. La vitesse de récupération influe directement sur l'impact business.