LiteLLM et les AI Gateways : reprendre le contrôle des coûts et de la sécurité de vos agents IA
- Published on
- Authors

- Name
- Sylvain BRUAS
- @sylvain_bruas

L'intelligence artificielle générative a changé la donne. Les entreprises expérimentes et commencent la mise en production d'agents IA capables d'orchestrer des tâches complexes : analyse de documents, génération de code, interaction client, automatisation de processus métier. Mais cette adoption rapide a un revers : les coûts. Et pas n'importe quels coûts — des coûts imprévisibles, qui peuvent exploser sans raison apparente, et qui échappent souvent aux mécanismes de contrôle traditionnels.
C'est dans ce contexte que les AI Gateways émergent comme une brique d'infrastructure essentielle. Et parmi les solutions disponibles, LiteLLM se distingue par sa capacité à se positionner en front d'Amazon Bedrock pour offrir le meilleur des deux mondes : la puissance et la flexibilité d'un catalogue de modèles de classe mondiale, combinées à un contrôle granulaire des coûts, de la sécurité et de la gouvernance.
Le problème : des coûts d'agents IA qui explosent sans prévenir
Contrairement à une API REST classique dont le coût par appel est relativement stable et prévisible, les agents IA introduisent une imprévisibilité structurelle dans la facturation. Plusieurs facteurs expliquent ce phénomène :
Les boucles d'appels récursifs. Un agent autonome peut décider, en fonction du contexte, d'appeler un modèle de langage (LLM) plusieurs dizaines de fois pour accomplir une seule tâche. Un agent de type ReAct (Reasoning + Acting) va typiquement alterner entre phases de réflexion et phases d'action, chaque itération générant un appel au LLM. Si la tâche est complexe ou si l'agent « tourne en rond » sur un problème, le nombre d'appels peut exploser sans qu'aucun mécanisme natif ne l'arrête.
L'explosion des tokens en contexte. Les agents modernes utilisent des fenêtres de contexte de plus en plus larges. Chaque appel successif inclut l'historique des échanges précédents, ce qui signifie que le nombre de tokens en entrée croît de manière quasi-exponentielle au fil de la conversation.
Les appels d'outils en cascade. Les agents modernes ne se contentent pas d'appeler un LLM. Ils orchestrent des outils : recherche web, requêtes en base de données, appels à d'autres API, génération d'images. Chaque outil peut lui-même déclencher des appels supplémentaires au LLM pour interpréter les résultats. Un seul prompt utilisateur peut ainsi générer des dizaines d'appels facturés.
L'absence de plafond natif. La plupart des fournisseurs de modèles facturent à l'usage sans mécanisme de plafonnement intégré. Si un agent s'emballe, rien ne l'arrête côté fournisseur — la facture continue de grimper jusqu'à ce qu'un humain intervienne ou que les quotas de rate limiting soient atteints.
Exemples d'explosion de coûts
Les témoignages se multiplient dans la communauté :
- Un développeur qui lance un agent de refactoring de code sur un repository entier et se retrouve avec une facture de plusieurs centaines de dollars en quelques heures, là où il attendait quelques dizaines.
- Une équipe data qui déploie un agent d'analyse de documents en production sans garde-fou : l'agent, confronté à des documents mal formatés, entre dans des boucles de retry qui multiplient les appels par 10.
- Un chatbot client qui, face à des requêtes ambiguës, génère des réponses de plus en plus longues en incluant tout l'historique de conversation, faisant exploser le coût par interaction.
Ces situations ne sont pas des cas extrêmes. Elles sont le résultat normal du fonctionnement des agents IA quand aucun mécanisme de contrôle n'est en place. Le problème n'est pas que les agents « dysfonctionnent » — c'est qu'ils fonctionnent exactement comme prévu, mais sans contrainte budgétaire.
Pourquoi les outils de FinOps traditionnels ne suffisent pas
Les outils de FinOps cloud classiques (AWS Cost Explorer, budgets Amazon CloudWatch, alertes de facturation) sont conçus pour des patterns de consommation relativement stables et prévisibles. Ils fonctionnent bien pour surveiller la consommation Amazon EC2 ou Amazon S3, mais ils sont inadaptés aux coûts d'IA générative pour plusieurs raisons :
- Granularité insuffisante : ils opèrent historiquement au niveau du compte ou du service. Bedrock propose désormais une attribution par principal IAM, mais sans mécanisme de coupure automatique au niveau applicatif.
- Latence des alertes : les alertes budgétaires AWS ont un délai de plusieurs heures. Un agent qui s'emballe peut consommer des centaines de dollars avant que l'alerte ne se déclenche.
- Pas de coupure automatique : une alerte budgétaire AWS notifie, mais ne coupe pas l'accès. L'agent continue de consommer pendant que l'équipe réagit.
- Pas de vision cross-provider : si vous utilisez plusieurs fournisseurs de modèles (Bedrock, OpenAI, Anthropic direct), chaque fournisseur a sa propre facturation, rendant la vision consolidée impossible.
La réponse : les AI Gateways
Qu'est-ce qu'un AI Gateway ?
Un AI Gateway est un proxy intelligent qui se positionne entre vos applications (agents, chatbots, pipelines) et les fournisseurs de modèles IA. Il agit comme un point de passage obligé pour tous les appels aux LLM, ce qui lui permet d'offrir des fonctionnalités transversales :
- Contrôle des coûts : budgets par équipe, par application, par utilisateur, avec coupure automatique quand le budget est atteint.
- Sécurité et gouvernance : authentification, autorisation, filtrage de contenu, audit des requêtes.
- Observabilité : logging centralisé de tous les appels, métriques de latence, de tokens consommés, de coûts en temps réel.
- Routage intelligent : redirection des requêtes vers différents modèles en fonction de critères (coût, latence, disponibilité, type de tâche).
- Abstraction du fournisseur : interface unifiée quel que soit le modèle sous-jacent (Claude, Llama, Mistral, Titan, etc.).
Pourquoi un point d'entrée unifié est essentiel
Sans AI Gateway, chaque équipe, chaque application accède directement aux modèles avec ses propres credentials, ses propres patterns d'appel, et sans visibilité centralisée. C'est l'équivalent de donner à chaque développeur un accès root à la base de données de production sans passer par un connection pooler ou un proxy SQL.
Un point d'entrée unifié permet de :
- Appliquer des politiques de sécurité cohérentes : filtrage de données sensibles (PII), blocage de certains types de requêtes, validation des inputs.
- Avoir une vision consolidée des coûts : qui consomme quoi, combien, et pour quel usage.
- Réagir en temps réel : couper un agent qui s'emballe, throttler une application qui consomme trop, rediriger vers un modèle moins coûteux en cas de pic.
- Simplifier la rotation des credentials : un seul point à mettre à jour quand les clés API changent.
- Faciliter la conformité : un seul point d'audit pour toutes les interactions avec les modèles IA.
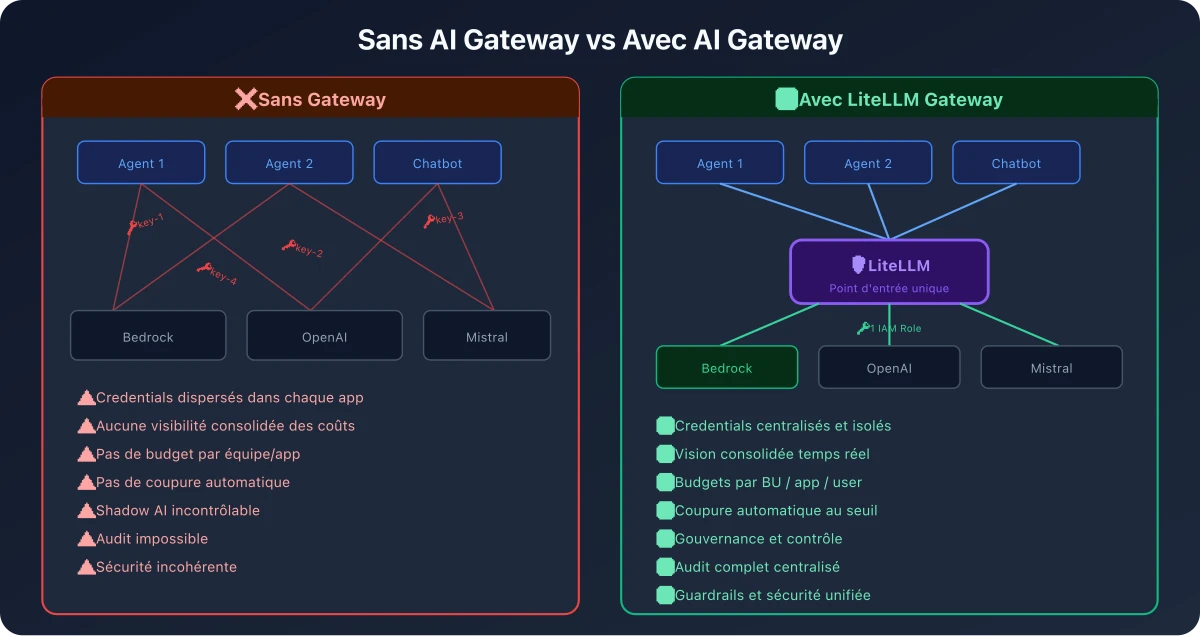
Une AI Gateway open source : LiteLLM
LiteLLM est un proxy open source qui fournit une interface compatible OpenAI pour plus de 100 fournisseurs de modèles IA. Concrètement, vos applications parlent à LiteLLM via l'API standard OpenAI (/chat/completions, /embeddings, etc.), et LiteLLM traduit ces appels vers le fournisseur de votre choix : Amazon Bedrock, Azure OpenAI, Anthropic, Mistral, Cohere, et bien d'autres.
C'est une plateforme complète de gestion des accès aux LLM qui inclut :
- Gestion des clés virtuelles : création de clés API avec des budgets, des limites de rate, et des permissions par modèle.
- Budgets par équipe et par utilisateur : définition de plafonds de dépenses avec coupure automatique.
- Routage et fallback : si un modèle est indisponible ou saturé, LiteLLM redirige automatiquement vers un modèle de secours.
- Guardrails : intégration de filtres de contenu, de détection de PII, et de politiques de sécurité.
- Dashboard d'observabilité : visualisation en temps réel des coûts, des tokens, de la latence, par clé, par équipe, par modèle.
- Cache sémantique : mise en cache des réponses pour des requêtes similaires, réduisant les coûts et la latence.
LiteLLM se déploie comme un service stateless (conteneur Docker) devant vos fournisseurs de modèles. Les applications communiquent avec LiteLLM via l'API compatible OpenAI, et LiteLLM route les requêtes vers le bon fournisseur en appliquant les politiques de sécurité, de budget et de routage.
LiteLLM en front d'Amazon Bedrock : le meilleur des deux mondes
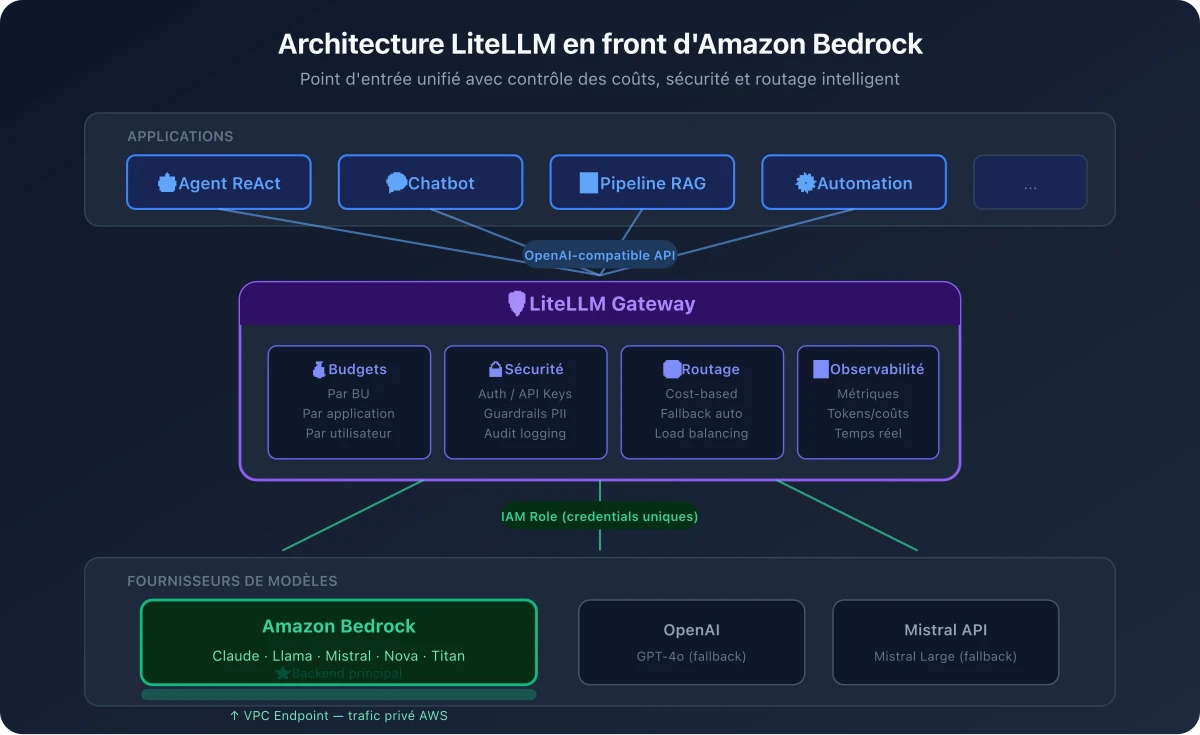
Pourquoi Bedrock comme backend ?
Amazon Bedrock est le service managé d'AWS qui donne accès à un catalogue de modèles fondamentaux (Foundation Models) de différents fournisseurs : Anthropic (Claude), Meta (Llama), Mistral, Amazon (Titan, Nova), Cohere, AI21 Labs, et d'autres. Bedrock offre plusieurs avantages structurels :
- Pas de gestion d'infrastructure : les modèles sont servis par AWS, vous n'avez pas à gérer de GPU, de scaling, ou de disponibilité.
- Intégration native AWS : IAM pour l'authentification, CloudTrail pour l'audit, VPC endpoints pour la connectivité privée, KMS pour le chiffrement.
- Données privées : vos données ne sont pas utilisées pour entraîner les modèles. Bedrock offre des garanties contractuelles sur ce point.
- Disponibilité régionale : Bedrock est disponible dans plusieurs régions européennes, et est disponible dans l'ESC avec une liste limitée de modèles.
Ce que LiteLLM ajoute à Bedrock
Bedrock est excellent pour servir des modèles, LiteLLM ajoute une interface unifiée et plus orientée vers les applications et utilisateurs.
Budgets granulaires avec enforcement. Bedrock offre désormais une attribution des coûts par principal IAM, mais il ne propose pas de mécanisme de coupure automatique quand un seuil est atteint. LiteLLM comble ce manque : il permet de définir des budgets par Business Unit, par application, par équipe, voire par utilisateur individuel, avec un enforcement en quasi temps réel. Quand le budget est atteint, l'accès est coupé automatiquement — pas besoin d'attendre une alerte CloudWatch avec 6 heures de retard.
# Exemple de configuration LiteLLM avec budgets par équipe
general_settings:
master_key: sk-litellm-master-key
model_list:
- model_name: claude-sonnet
litellm_params:
model: bedrock/us.anthropic.claude-sonnet-4-6
aws_region_name: us-east-1
- model_name: claude-haiku
litellm_params:
model: bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0
aws_region_name: us-east-1
- model_name: mistral-7b
litellm_params:
model: bedrock/converse/mistral.mistral-7b-instruct-v0:2
aws_region_name: us-east-1
Côté gestion des équipes et budgets, LiteLLM expose une API d'administration :
# Créer une équipe avec un budget mensuel
curl -X POST 'http://litellm:4000/team/new' \
-H 'Authorization: Bearer sk-litellm-master-key' \
-H 'Content-Type: application/json' \
-d '{
"team_alias": "equipe-data",
"max_budget": 500,
"budget_duration": "1mo",
"models": ["claude-sonnet", "claude-haiku"],
"metadata": {"bu": "data-engineering"}
}'
# Créer une clé pour un développeur avec son propre budget
curl -X POST 'http://litellm:4000/key/generate' \
-H 'Authorization: Bearer sk-litellm-master-key' \
-H 'Content-Type: application/json' \
-d '{
"team_id": "team-xxx",
"max_budget": 50,
"budget_duration": "1mo",
"models": ["claude-haiku"],
"metadata": {"user": "jean.dupont@entreprise.fr"}
}'
Routage par coût. LiteLLM peut automatiquement router les requêtes vers le modèle le moins coûteux capable de traiter la tâche. Par exemple, les requêtes simples (classification, extraction) sont envoyées vers Claude Haiku (peu coûteux), tandis que les tâches complexes (raisonnement, génération longue) sont dirigées vers Claude Sonnet.
Fallback automatique. Si Bedrock dans une région est saturé ou indisponible, LiteLLM peut automatiquement basculer vers une autre région ou un autre fournisseur, sans interruption pour l'application.
L'ancienne pièce manquante côté AWS : l'attribution granulaire native de Bedrock
Depuis avril 2026, AWS a comblé une lacune avec l'attribution granulaire des coûts pour Amazon Bedrock. Bedrock attribue désormais automatiquement les coûts d'inférence au principal IAM qui effectue l'appel. Dans le Cost and Usage Report (CUR 2.0), une nouvelle colonne line_item_iam_principal identifie précisément qui consomme : un utilisateur IAM, un rôle applicatif, ou une identité fédérée.
Combiné à des tags IAM (principal tags sur les rôles/utilisateurs, ou session tags passés dynamiquement), on peut agréger les coûts par équipe, projet ou centre de coûts directement dans AWS Cost Explorer.
Le cas spécifique des AI Gateways. L'article AWS identifie explicitement le scénario d'un LLM gateway en front de Bedrock. Sans configuration supplémentaire, tout le trafic est attribué au rôle unique du gateway — aucune visibilité par utilisateur. La solution recommandée : le gateway effectue un AssumeRole par utilisateur avec un --role-session-name identifiant l'appelant et des --tags de session (équipe, tenant, centre de coûts). Les credentials sont cachées avec un TTL d'une heure, ce qui limite les appels STS à un par utilisateur par heure.
# Exemple : le gateway assume un rôle Bedrock pour chaque utilisateur
aws sts assume-role \
--role-arn arn:aws:iam::123456789012:role/BedrockInvocationRole \
--role-session-name "gw-jean.dupont" \
--tags Key=team,Value=data-engineering Key=cost-center,Value=BU-DATA
Ce qui apparaît alors dans CUR 2.0 :
line_item_iam_principal | line_item_usage_type | tags |
|---|---|---|
…assumed-role/BedrockRole/gw-jean.dupont | EUW3-Claude4Sonnet-input-tokens | {"iamPrincipal/team":"data-engineering"} |
…assumed-role/BedrockRole/gw-tenant-acme | EUW3-Claude4Sonnet-output-tokens | {"iamPrincipal/tenant":"acme-corp"} |
Complémentarité avec LiteLLM. Cette attribution native ne remplace pas LiteLLM — elle le complète. Bedrock fournit désormais la visibilité passive (qui consomme quoi dans la facturation AWS), tandis que LiteLLM assure le contrôle actif (coupure automatique quand un budget est atteint, rate limiting par clé, routage par coût, guardrails). Les deux ensemble offrent une gouvernance FinOps complète :
- Bedrock + CUR 2.0 : attribution, reporting, chargeback, analyse a posteriori via Cost Explorer
- LiteLLM : enforcement en temps réel, coupure automatique, routage intelligent, abstraction multi-modèle
En pratique, si vous déployez LiteLLM en front de Bedrock, configurez-le pour utiliser des sessions STS par utilisateur. Vous obtiendrez à la fois le contrôle temps réel de LiteLLM et l'attribution native dans votre facturation AWS — le meilleur des deux mondes, littéralement.
Budgets par BU, par application : la gouvernance FinOps de l'IA
L'un des cas d'usage les plus puissants de LiteLLM en front de Bedrock est la capacité à implémenter une gouvernance FinOps granulaire pour l'IA générative. Voici comment structurer les budgets dans une organisation :
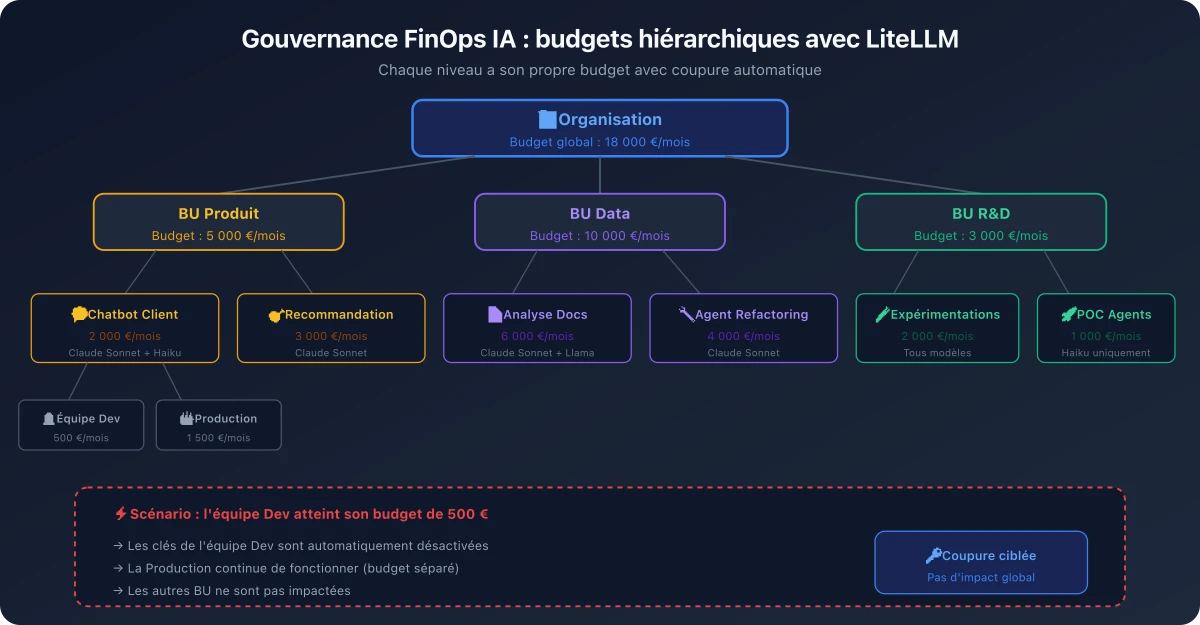
Chaque niveau de la hiérarchie a son propre budget. Si l'équipe Dev du chatbot atteint ses 500 € mensuels, ses clés sont désactivées automatiquement — mais le reste de la BU Produit continue de fonctionner. Si c'est toute la BU Produit qui atteint ses 5 000 €, toutes les applications de cette BU sont coupées, mais les autres BU ne sont pas impactées.
Sécurité : une couche unifiée indispensable
Les risques de sécurité spécifiques aux LLM
Les agents IA introduisent des vecteurs d'attaque spécifiques qui nécessitent des contrôles dédiés :
- Injection de prompt : un utilisateur malveillant peut tenter de manipuler l'agent pour qu'il exécute des actions non autorisées ou divulgue des informations sensibles.
- Exfiltration de données : un agent qui a accès à des données internes peut être manipulé pour les inclure dans ses réponses.
- Fuite de PII : les modèles peuvent involontairement inclure des données personnelles dans leurs réponses si elles sont présentes dans le contexte.
- Abus de ressources : un utilisateur peut intentionnellement déclencher des boucles coûteuses pour nuire à l'organisation.
- Shadow AI : sans point d'entrée centralisé, les équipes utilisent des clés API personnelles, contournant toute politique de sécurité.
Ce que LiteLLM apporte en termes de sécurité
Authentification et autorisation centralisées. Chaque appel passe par LiteLLM avec une clé API qui identifie l'appelant. Plus besoin de distribuer des credentials Bedrock (access keys IAM) à chaque application — LiteLLM gère l'authentification côté application et utilise un seul rôle IAM pour accéder à Bedrock.
Guardrails et filtrage de contenu. LiteLLM s'intègre avec des solutions de guardrails (Bedrock Guardrails, Lakera Guard, Presidio) pour :
- Détecter et masquer les PII dans les requêtes et les réponses
- Bloquer les tentatives d'injection de prompt
- Filtrer le contenu inapproprié ou dangereux
- Appliquer des politiques de contenu spécifiques à l'organisation
Audit complet. Chaque requête est loggée avec : l'identité de l'appelant, le modèle utilisé, le nombre de tokens, le coût, la latence, et optionnellement le contenu de la requête et de la réponse. Ces logs peuvent être envoyés vers des solutions SIEM pour analyse et détection d'anomalies.
Isolation des credentials. Les applications n'ont jamais accès aux credentials AWS sous-jacentes. Si une clé LiteLLM est compromise, elle peut être révoquée instantanément sans impacter les autres applications. Et la clé compromise n'a accès qu'aux modèles et budgets qui lui ont été attribués — pas à l'ensemble de l'infrastructure AWS.
Contrôle des modèles accessibles. Vous pouvez restreindre quels modèles sont accessibles par quelle équipe. Par exemple, seule l'équipe R&D a accès à Claude Opus (le plus coûteux), tandis que les équipes produit sont limitées à Haiku et Sonnet.
Architecture de sécurité recommandée
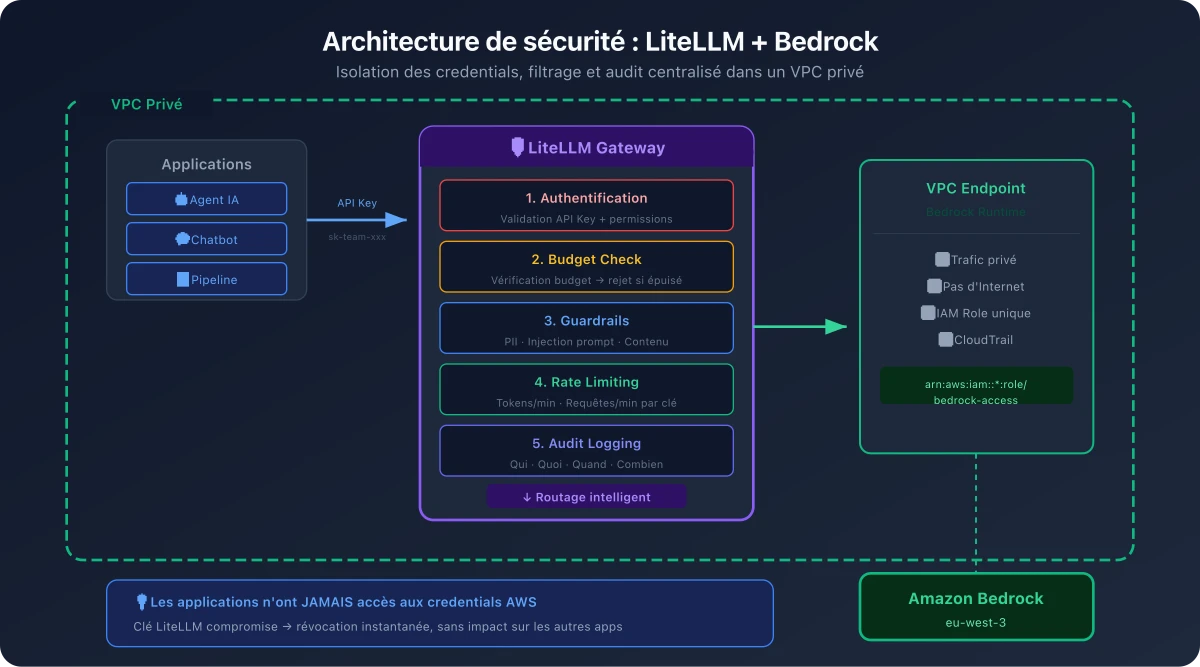
Dans cette architecture :
- Le trafic ne sort jamais du réseau AWS (VPC endpoint vers Bedrock)
- LiteLLM est le seul composant qui possède les credentials Bedrock
- Les applications s'authentifient auprès de LiteLLM avec des clés virtuelles à permissions limitées
- Tous les appels sont audités et filtrés
Mise en œuvre pratique
Déploiement de LiteLLM sur AWS
LiteLLM se déploie facilement sur AWS via plusieurs options :
- Amazon ECS/AWS Fargate : déploiement conteneurisé serverless, idéal pour la production.
- Amazon EKS : si vous avez déjà un cluster Kubernetes.
- EC2 : pour un déploiement simple ou un POC.
Le conteneur LiteLLM nécessite une base de données PostgreSQL pour stocker les clés, les budgets et les métriques. Amazon RDS PostgreSQL ou Aurora Serverless conviennent parfaitement.
Configuration du routage vers Bedrock
La configuration de LiteLLM pour router vers Bedrock est directe. L'authentification utilise le chaînage standard des credentials AWS (rôle IAM de l'instance, variables d'environnement, ou profil) :
model_list:
- model_name: claude-sonnet
litellm_params:
model: bedrock/us.anthropic.claude-sonnet-4-6
aws_region_name: us-east-1
- model_name: claude-haiku
litellm_params:
model: bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0
aws_region_name: us-east-1
- model_name: mistral-7b
litellm_params:
model: bedrock/converse/mistral.mistral-7b-instruct-v0:2
aws_region_name: us-east-1
router_settings:
routing_strategy: "least-busy" # ou "cost-based", "latency-based"
num_retries: 2
timeout: 30
allowed_fails: 1
Intégration côté application
Côté application, le changement est minimal. Puisque LiteLLM expose une API compatible OpenAI, il suffit de changer l'URL de base :
from openai import OpenAI
# Avant : appel direct à Bedrock via boto3
# Après : appel via LiteLLM avec contrôle des coûts
client = OpenAI(
api_key="sk-team-data-key-xxx", # Clé avec budget
base_url="http://litellm.internal:4000"
)
response = client.chat.completions.create(
model="claude-sonnet",
messages=[{"role": "user", "content": "Analyse ce document..."}],
max_tokens=4096
)
Toute bibliothèque compatible OpenAI (LangChain, LlamaIndex, CrewAI, AutoGen) fonctionne nativement avec LiteLLM sans modification de code — il suffit de pointer vers l'URL du proxy.
Retour d'expérience et bonnes pratiques
Commencer petit, itérer vite
Ne déployez pas LiteLLM en production pour toute l'organisation d'un coup. Commencez par une équipe pilote, validez les patterns de budgets et de routage, puis étendez progressivement.
Définir des budgets réalistes
Analysez la consommation actuelle avant de fixer des budgets. Un budget trop serré bloque les équipes et génère de la frustration. Un budget trop large ne protège de rien. Commencez avec des budgets généreux et resserrez progressivement en fonction des données réelles.
Monitorer les anomalies, pas seulement les totaux
Le coût total mensuel est un indicateur retardé. Surveillez plutôt :
- Le coût par requête (détecte les agents qui s'emballent)
- Le nombre de tokens par session (détecte les contextes qui explosent)
- Le ratio input/output tokens (détecte les prompts mal optimisés)
- Les pics soudains de consommation (détecte les boucles infinies)
Implémenter des circuit breakers
Au-delà des budgets, implémentez des mécanismes de circuit breaker au niveau applicatif : si un agent dépasse un certain nombre d'itérations ou un certain coût par session, il doit s'arrêter et remonter une alerte plutôt que de continuer à consommer.
Conclusion
L'adoption des agents IA en entreprise est en marche. Mais sans gouvernance adaptée, les coûts peuvent devenir un frein majeur — voire un risque financier. Les outils de FinOps traditionnels ne sont pas conçus pour la granularité et la réactivité qu'exige l'IA générative.
LiteLLM en front d'Amazon Bedrock offre une réponse pragmatique à ce défi. Vous conservez la puissance de Bedrock — son catalogue de modèles, son intégration AWS native, ses garanties de confidentialité — tout en ajoutant la couche de contrôle qui manque : budgets par BU et par application, sécurité unifiée, observabilité en temps réel, et routage intelligent.
C'est l'approche que je recommande pour la production avec l'IA générative : ne laissez pas vos agents en roue libre. Mettez un gateway devant, définissez des budgets, et gardez le contrôle. La flexibilité de Bedrock combinée au contrôle de LiteLLM, c'est exactement le compromis dont les entreprises ont besoin pour scaler l'IA de manière responsable.