EC2 Capacity Reservations, Savings Plans et Reserved Instances : garantir la disponibilité tout en optimisant les coûts
- Published on
- Authors

- Name
- Sylvain BRUAS
- @sylvain_bruas

Il y a quelques semaines, un de mes clients a rencontré un incident qui illustre un risque souvent sous-estimé sur AWS : pendant 45 minutes, impossible de lancer de nouvelles instances Amazon Elastic Compute Cloud (EC2) d'un type spécifique sur la région eu-west-3 (Paris). L'Auto Scaling Group tentait de scaler, mais chaque tentative se soldait par la même erreur : InsufficientInstanceCapacity. Le service s'est dégradé et les utilisateurs ont été impactés.
Qu'est-ce qu'une erreur InsufficientInstanceCapacity (ICE) ?
Quand vous lancez une instance EC2, AWS doit trouver un serveur physique disponible dans l'Availability Zone (AZ) demandée, avec le bon type d'instance et suffisamment de ressources. Si cette capacité n'est pas disponible à cet instant précis, AWS retourne l'erreur InsufficientInstanceCapacity.
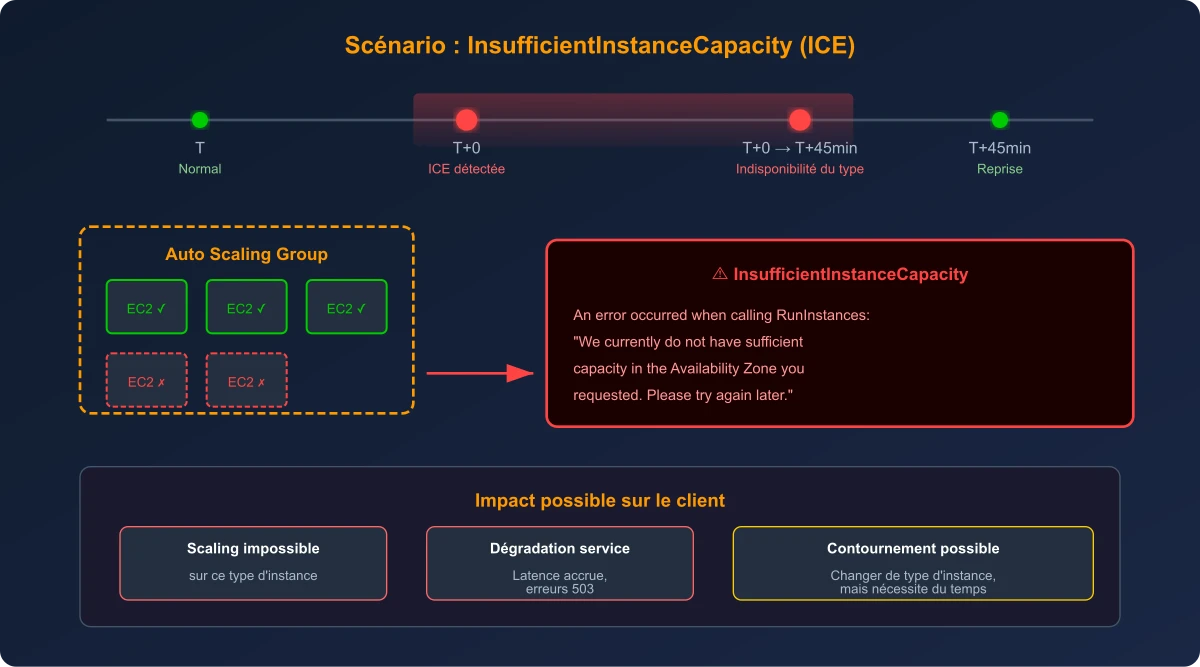
Scénario réel : une erreur ICE empêche le scaling pendant 45 minutes sur la région Paris
Il est important de comprendre que cette erreur n'est pas liée à vos quotas de compte (Service Quotas). Vos limites peuvent être parfaitement suffisantes, mais si AWS n'a physiquement plus de serveurs disponibles pour le type d'instance demandé dans l'AZ ciblée, le lancement échouera. C'est une contrainte d'infrastructure physique.
Les erreurs ICE sont plus fréquentes dans certaines situations :
- Régions à forte demande : Paris (eu-west-3) est une région plus petite que us-east-1 ou eu-west-1, avec moins de capacité physique disponible
- Types d'instances spécifiques : les instances GPU, les très grandes tailles (metal, 24xlarge) ou les générations récentes peuvent avoir une disponibilité limitée
- Pics de demande : événements commerciaux, fins de mois, ou simplement une forte activité simultanée dans la même AZ
- Mono-AZ : concentrer toute sa charge dans une seule Availability Zone augmente considérablement le risque
Dans le cas de mon client, l'ASG était configuré sur un seul type d'instance dans deux AZ. Quand la capacité s'est raréfiée pour ce type d'instance sur les deux zones simultanément, plus aucun scaling n'était possible.
Reserved Instances : comprendre la différence entre régionale et zonale
Avant de parler de la solution moderne, il faut comprendre le mécanisme historique des Reserved Instances (RI) et une distinction fondamentale que beaucoup d'architectes négligent : la portée régionale versus zonale.
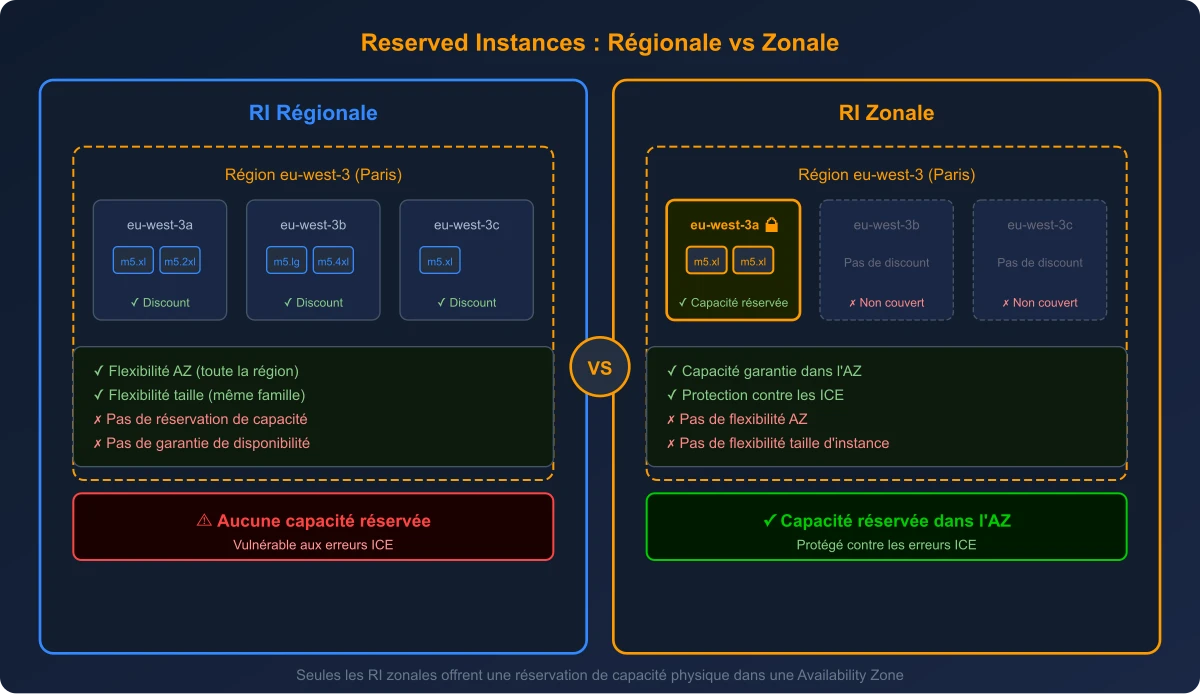
Comparaison des deux types de Reserved Instances et leur impact sur la réservation de capacité
Reserved Instance régionale
Quand vous achetez une RI avec une portée régionale, la réduction tarifaire s'applique automatiquement à toute instance correspondante dans n'importe quelle AZ de la région. Mieux encore, elle offre une flexibilité de taille au sein de la même famille d'instances (sur Linux/Unix avec tenancy par défaut). Par exemple, une RI régionale m5 peut couvrir aussi bien des m5.large que des m5.xlarge, en ajustant via un facteur de normalisation.
Mais attention : une RI régionale ne réserve aucune capacité physique. C'est uniquement une réduction de facturation. Si une erreur ICE survient, votre RI régionale ne vous protège absolument pas. Vous avez la réduction, mais pas la garantie de pouvoir lancer vos instances.
Reserved Instance zonale
Une RI zonale est achetée pour une AZ spécifique (par exemple eu-west-3a). Elle offre la même réduction tarifaire, mais avec un avantage majeur : elle réserve de la capacité physique dans cette AZ. AWS vous garantit que la capacité correspondante sera disponible.
Le compromis est la perte de flexibilité : pas de flexibilité d'AZ (la réduction ne s'applique que dans l'AZ choisie) et pas de flexibilité de taille (elle ne couvre que le type et la taille exacts achetés).
Le dilemme des RI
C'est là que le bât blesse. Avec les Reserved Instances, vous devez choisir entre :
- Flexibilité (RI régionale) : réduction applicable partout, mais aucune garantie de capacité
- Garantie de capacité (RI zonale) : capacité réservée, mais rigidité totale sur l'AZ et le type d'instance
Et dans les deux cas, vous êtes engagé sur 1 ou 3 ans, sur un type d'instance spécifique. Si vos besoins évoluent, vous êtes coincé (ou vous devez passer par le marketplace RI pour revendre, avec des contraintes).
On-Demand Capacity Reservations + Savings Plans : la flexibilité retrouvée
C'est ici que la combinaison ODCR + Savings Plans change la donne. Cette approche découple deux préoccupations qui étaient historiquement liées avec les RI : la réservation de capacité et la réduction tarifaire.
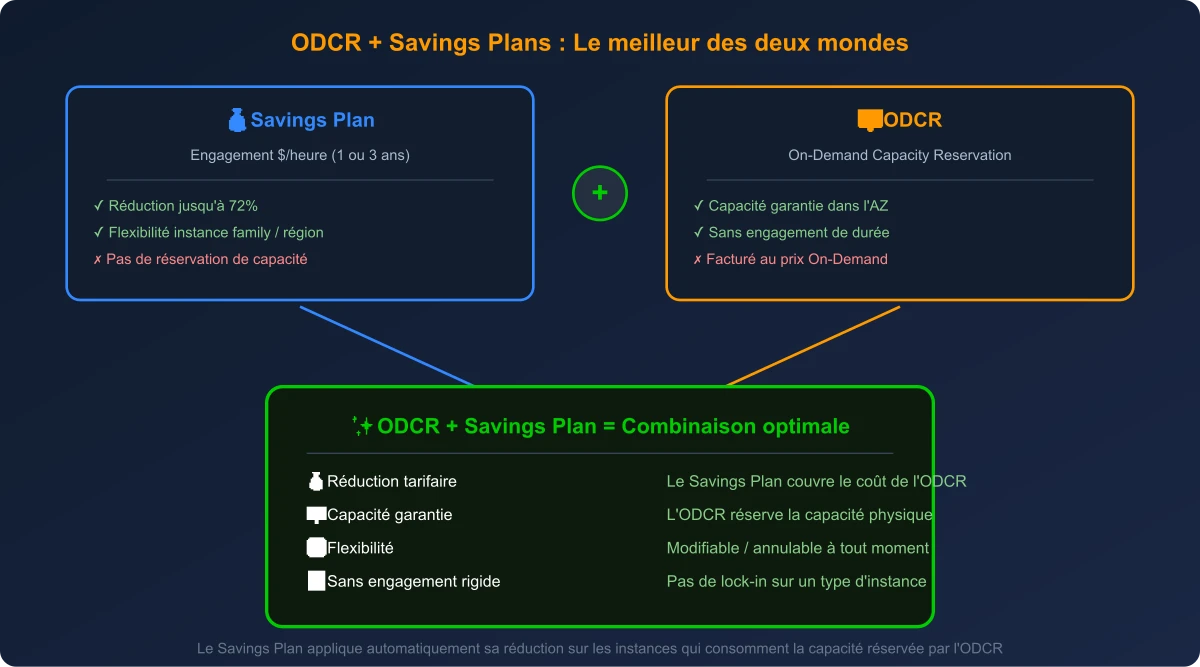
La combinaison ODCR + Savings Plans offre à la fois la garantie de capacité et la réduction tarifaire
On-Demand Capacity Reservations (ODCR)
Les ODCR vous permettent de réserver de la capacité EC2 dans une AZ spécifique, pour un type d'instance donné, sans aucun engagement de durée. Vous pouvez créer une ODCR le lundi et l'annuler le vendredi si vous n'en avez plus besoin. Vous pouvez aussi la modifier : augmenter ou diminuer le nombre d'instances réservées à tout moment.
Les ODCR peuvent être « open » (toute instance correspondante dans votre compte les utilise automatiquement) ou « targeted » (seules les instances explicitement configurées les consomment). Elles sont compatibles avec les services managés comme Amazon EC2 Auto Scaling, Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS) et d'autres.
Le point important : une ODCR seule est facturée au tarif On-Demand, que la capacité soit utilisée ou non. C'est là que le Savings Plan entre en jeu.
Savings Plans
Les Savings Plans sont un engagement de dépense en dollars par heure, sur 1 ou 3 ans. En échange, vous bénéficiez d'une réduction pouvant atteindre 72 % par rapport au tarif On-Demand. Il existe deux types principaux pour EC2 :
- Compute Savings Plans : la réduction s'applique à tout usage compute éligible (EC2, AWS Fargate, AWS Lambda), quelle que soit la famille d'instance, la taille, l'OS, la tenancy ou la région. C'est le plus flexible.
- EC2 Instance Savings Plans : la réduction est limitée à une famille d'instances dans une région donnée, mais elle est légèrement plus élevée. Vous gardez la flexibilité sur la taille, l'OS et la tenancy.
La combinaison gagnante
Quand vous combinez ODCR et Savings Plans, voici ce qui se passe :
- L'ODCR réserve la capacité physique dans l'AZ → vous êtes protégé contre les erreurs ICE
- Le Savings Plan applique automatiquement sa réduction sur les instances qui consomment cette capacité → vous payez le tarif réduit, pas le tarif On-Demand
- L'ODCR reste modifiable et annulable indépendamment du Savings Plan → vous ajustez la capacité réservée selon vos besoins réels
Vous obtenez ainsi le meilleur des deux mondes : la garantie de capacité d'une RI zonale avec la flexibilité tarifaire d'un Savings Plan. Et si demain vous changez de type d'instance ou de région, votre Savings Plan suivra automatiquement.
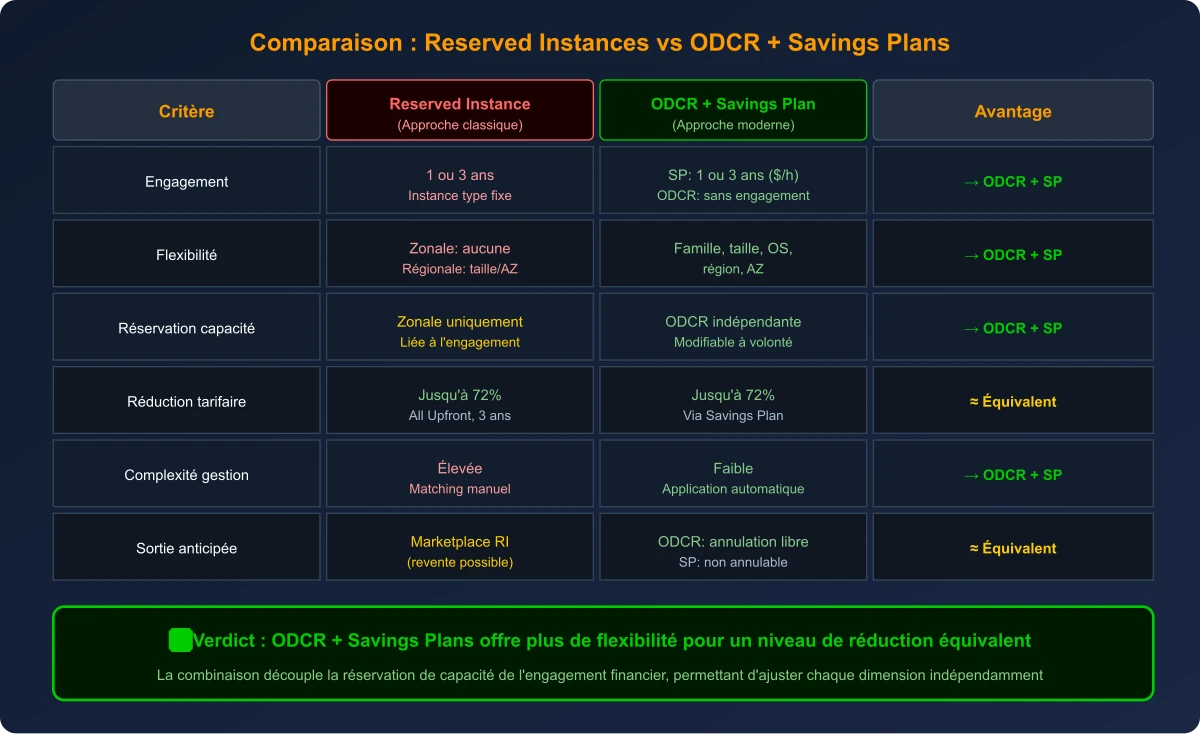
Sur presque tous les critères, la combinaison ODCR + Savings Plans surpasse les Reserved Instances classiques
Bonnes pratiques pour les EC2 Capacity Reservations
La mise en place d'ODCR nécessite une approche réfléchie pour maximiser leur valeur sans gaspiller de budget. Voici les bonnes pratiques issues de la documentation AWS et de mon expérience terrain.

Les six bonnes pratiques essentielles pour une gestion efficace des ODCR
Répartir sur plusieurs Availability Zones
Ne concentrez jamais toute votre capacité réservée dans une seule AZ. Répartissez vos ODCR sur au moins deux, idéalement trois AZ. Cela vous protège non seulement contre les ICE localisées, mais aussi contre les pannes d'AZ. Dimensionnez chaque ODCR pour supporter la charge minimale de votre application dans cette zone.
Toujours coupler avec un Savings Plan
Une ODCR sans Savings Plan, c'est payer le plein tarif On-Demand pour de la capacité réservée. Assurez-vous que votre engagement Savings Plan couvre au minimum le coût de vos ODCR. Le Savings Plan s'applique automatiquement, il n'y a aucune configuration supplémentaire à faire.
Monitorer l'utilisation avec Amazon CloudWatch
AWS fournit des métriques CloudWatch pour suivre le taux d'utilisation de vos ODCR. Une capacité réservée mais inutilisée coûte exactement le même prix qu'une instance active. Mettez en place des alarmes pour détecter les ODCR sous-utilisées et ajustez-les régulièrement. L'objectif est de maintenir un taux d'utilisation proche de 100 %.
Choisir entre Open et Targeted
Les ODCR « open » sont automatiquement consommées par toute instance correspondante dans votre compte. C'est pratique mais risqué dans un environnement multi-équipes : une équipe peut involontairement consommer la capacité réservée pour une autre. Préférez les ODCR « targeted » pour les workloads critiques, en configurant explicitement quelles instances ou quels ASG doivent les utiliser.
Utiliser les Capacity Reservation Groups
Les groupes de réservation permettent de regrouper plusieurs ODCR (potentiellement dans différentes AZ) sous une même entité logique. Combinés avec AWS Resource Access Manager (RAM), vous pouvez partager ces groupes entre comptes d'une même organisation AWS. C'est indispensable dans une architecture multi-comptes.
Exploiter Split, Move et Modify
AWS a introduit en mars 2025 trois fonctionnalités pour gérer les ODCR de manière plus granulaire :
- Split : diviser une ODCR existante en plusieurs réservations plus petites. Typiquement, si votre équipe ML dispose d'une ODCR de 10 instances mais n'en utilise que 5, vous pouvez détacher les 5 inutilisées pour créer une nouvelle ODCR destinée à une autre équipe.
- Move : déplacer de la capacité inutilisée d'une ODCR vers une autre, sans recréer de réservation. Utile pour rééquilibrer la capacité entre projets au fil du temps.
- Modify : ajuster les attributs d'une ODCR existante (quantité d'instances, éligibilité open/targeted, date de fin) sans perturber les workloads en cours.
Ces opérations sont particulièrement puissantes combinées avec les Capacity Reservation Groups et AWS Resource Access Manager (RAM). Après un split, vous pouvez partager la nouvelle ODCR avec un autre compte de votre organisation via RAM. Cela permet une gestion centralisée de la capacité au niveau de l'organisation : un compte « plateforme » détient les ODCR et les redistribue aux comptes applicatifs selon les besoins, tout en gardant le contrôle sur l'allocation globale.
Monitorer avec Amazon EC2 Capacity Manager
Depuis octobre 2025, AWS propose Amazon EC2 Capacity Manager, une interface centralisée pour surveiller, analyser et gérer l'utilisation de la capacité EC2 sur l'ensemble de vos comptes et régions. Ce service est disponible sans frais supplémentaires dans toutes les régions commerciales.
EC2 Capacity Manager consolide dans un tableau de bord unique les données de capacité qui nécessitaient auparavant de naviguer entre la console EC2, CloudWatch, les Cost and Usage Reports et les API describe. Concrètement, il offre :
- Vue multi-comptes et multi-régions : visualisez l'utilisation des instances On-Demand, Spot et des Capacity Reservations à travers toute votre organisation AWS, avec un rafraîchissement horaire des données.
- Tendances historiques : analysez les patterns d'utilisation sur les 90 derniers jours (ou plus via l'export S3) pour identifier les périodes de sous-utilisation et ajuster vos réservations en conséquence.
- Opportunités d'optimisation priorisées : le service identifie automatiquement les ODCR sous-utilisées, classées par impact financier. Par exemple, 100 heures vCPU inutilisées sur des instances
p5représentent un coût bien plus élevé que sur dest3. - Actions directes : depuis l'interface, vous pouvez modifier les paramètres d'une ODCR (quantité, éligibilité, date de fin) sans naviguer vers d'autres sections de la console.
- Export de données : exportez les métriques vers Amazon Simple Storage Service (S3) pour une analyse à long terme ou une intégration avec vos outils de BI existants.
Pour les organisations qui gèrent des dizaines d'ODCR réparties sur plusieurs comptes, EC2 Capacity Manager remplace avantageusement les scripts maison et les tableaux de bord CloudWatch personnalisés. C'est l'outil qui manquait pour piloter efficacement une stratégie ODCR à l'échelle.
ODCR comme baseline d'un Auto Scaling Group avec Spot pour le scaling
C'est la stratégie que j'ai mise en place chez mon client après l'incident ICE, et c'est à mon sens le meilleur compromis entre coût, disponibilité et élasticité.
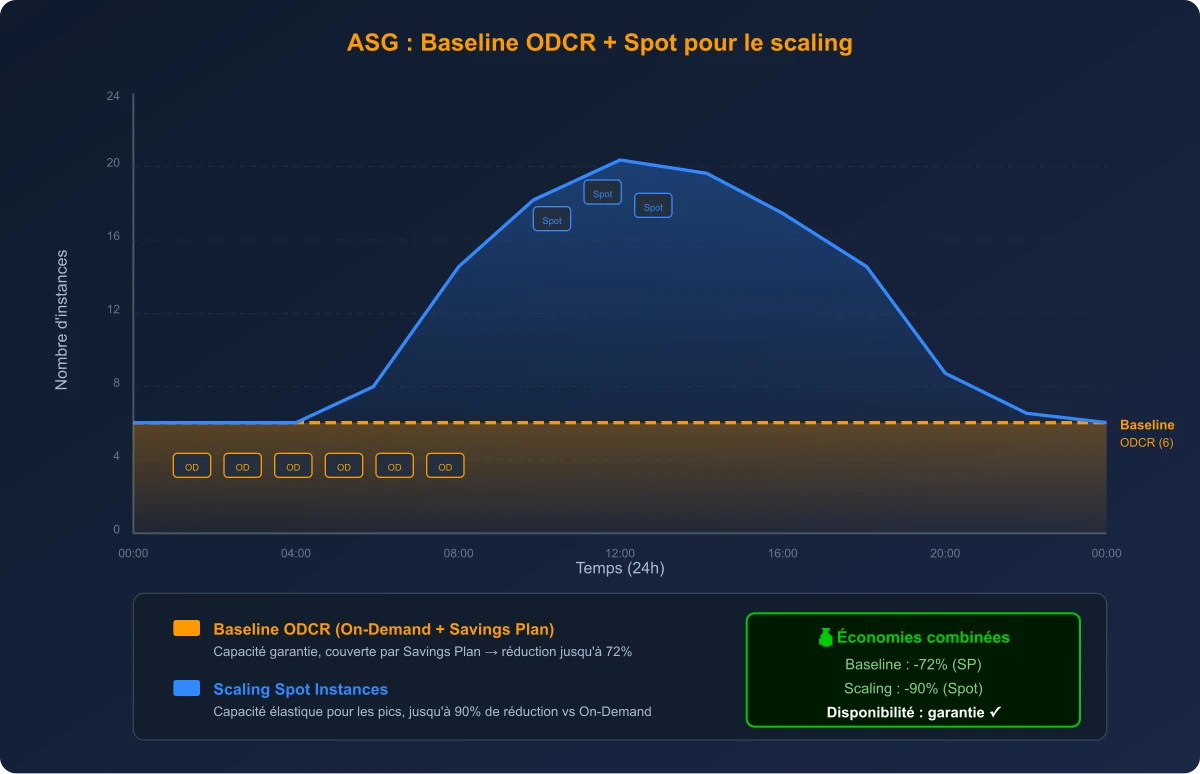
Le mix optimal : ODCR pour la baseline garantie, Spot Instances pour le scaling élastique
Le principe
L'idée est simple : séparer votre flotte EC2 en deux couches au sein du même Auto Scaling Group grâce à une Mixed Instances Policy :
-
La baseline (ODCR + Savings Plan) : c'est le nombre minimum d'instances dont votre application a besoin en permanence pour fonctionner correctement. Ces instances sont couvertes par des ODCR (capacité garantie) et un Savings Plan (réduction tarifaire). Elles ne seront jamais impactées par une erreur ICE car la capacité est physiquement réservée.
-
Le scaling (Spot Instances) : pour absorber les pics de charge au-delà de la baseline, vous utilisez des Spot Instances. Elles offrent jusqu'à 90 % de réduction par rapport au tarif On-Demand, mais peuvent être interrompues avec un préavis de 2 minutes.
Configuration de l'ASG
Dans la configuration de votre Auto Scaling Group, vous définissez :
- Le minimum capacity correspond à votre baseline ODCR (par exemple 6 instances réparties sur 3 AZ)
- Le desired capacity s'ajuste dynamiquement selon la charge
- Le maximum capacity définit la limite haute, atteinte avec des Spot Instances
- La Mixed Instances Policy spécifie le ratio On-Demand / Spot : les premières instances lancées sont On-Demand (et consomment les ODCR), le scaling additionnel utilise des Spot
{
"MixedInstancesPolicy": {
"InstancesDistribution": {
"OnDemandBaseCapacity": 6,
"OnDemandPercentageAboveBaseCapacity": 0,
"SpotAllocationStrategy": "capacity-optimized"
},
"LaunchTemplate": {
"Overrides": [
{ "InstanceType": "m5.xlarge" },
{ "InstanceType": "m5a.xlarge" },
{ "InstanceType": "m5n.xlarge" },
{ "InstanceType": "m6i.xlarge" }
]
}
}
}
Le paramètre OnDemandBaseCapacity: 6 garantit que les 6 premières instances seront toujours On-Demand (et donc couvertes par vos ODCR). Le OnDemandPercentageAboveBaseCapacity: 0 indique que tout scaling au-delà de cette baseline utilisera des Spot Instances.
Diversifier les types d'instances pour le Spot
Pour maximiser la disponibilité des Spot Instances, spécifiez plusieurs types d'instances compatibles dans les Overrides. La stratégie capacity-optimized demande à AWS de choisir automatiquement le pool Spot avec le plus de capacité disponible, réduisant ainsi le risque d'interruption.
Les économies réalisées
Prenons un exemple concret avec une baseline de 6 instances m5.xlarge et un pic à 18 instances :
- Baseline (6 instances) : couvertes par ODCR + Savings Plan → réduction de ~72 % vs On-Demand
- Scaling (12 instances Spot) : réduction de ~70-90 % vs On-Demand
- Coût moyen pondéré : environ 75-80 % de réduction par rapport à un déploiement 100 % On-Demand
Et surtout, la baseline est garantie disponible grâce aux ODCR. Même si une erreur ICE survient, vos 6 instances de base sont protégées. Seul le scaling Spot pourrait être temporairement impacté, mais votre service reste opérationnel à sa capacité minimale.
Gérer les interruptions Spot
Pour que cette architecture soit robuste, préparez votre application aux interruptions Spot :
- Utilisez les notifications d'interruption Spot (2 minutes de préavis) pour drainer proprement les connexions
- Configurez le Capacity Rebalancing dans l'ASG pour remplacer proactivement les instances à risque
- Assurez-vous que votre application est stateless ou que l'état est externalisé (Amazon ElastiCache, Amazon DynamoDB, Amazon Elastic File System)
- Mettez en place des health checks robustes pour que l'ALB retire rapidement les instances en cours d'interruption
Quelle stratégie choisir ? L'arbre de décision
Pour résumer les différentes options et vous aider à choisir la bonne stratégie selon votre contexte, voici un arbre de décision.
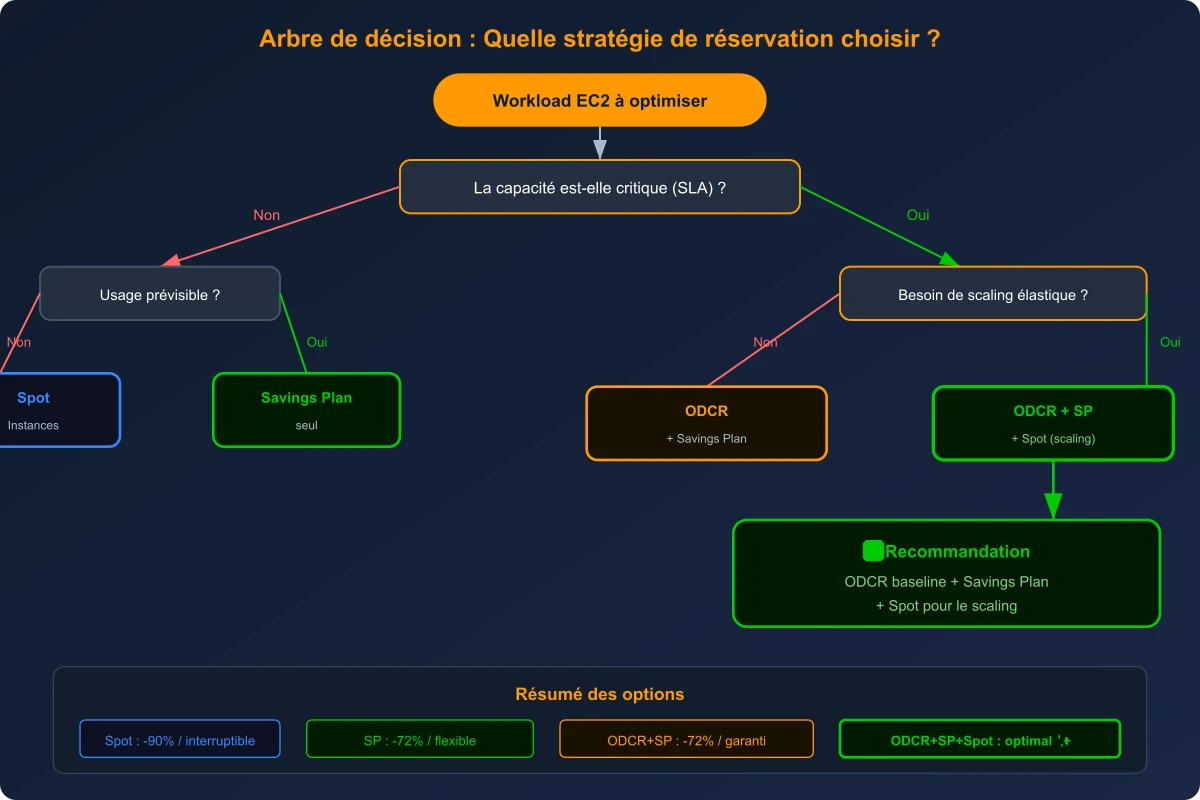
Choisissez votre stratégie de réservation en fonction de vos contraintes de disponibilité et d'élasticité
- Workload non critique, usage imprévisible → Spot Instances seules (économies maximales, interruptions acceptées)
- Workload non critique, usage prévisible → Savings Plan seul (réduction tarifaire sans réservation de capacité)
- Workload critique, pas de scaling → ODCR + Savings Plan (capacité garantie + réduction)
- Workload critique avec scaling → ODCR baseline + Savings Plan + Spot scaling (le mix optimal)
Retour sur l'incident : ce qui a changé
Après la mise en place de cette architecture chez mon client, voici les changements concrets :
- ODCR créées sur 3 AZ de eu-west-3, couvrant la baseline de 3 instances (1 par AZ)
- Compute Savings Plan souscrit pour couvrir l'engagement horaire correspondant
- Mixed Instances Policy configurée avec
OnDemandBaseCapacity: 3et Spot pour le scaling - Plusieurs types d'instances dans les overrides pour diversifier le pool Spot
- Monitoring CloudWatch avec alertes sur l'utilisation des ODCR et les interruptions Spot
Conclusion
L'erreur InsufficientInstanceCapacity est un rappel que le cloud n'est pas une ressource infinie. La capacité physique a des limites, et sans précaution, votre application peut se retrouver dans l'impossibilité de scaler au pire moment.
La combinaison ODCR + Savings Plans représente une évolution majeure par rapport aux Reserved Instances classiques. Elle offre la même garantie de capacité et le même niveau de réduction et plus de flexibilité . Ajoutez-y des Spot Instances pour le scaling, et vous obtenez une architecture qui maximise les économies tout en garantissant la disponibilité de votre baseline.
Si vous opérez des workloads critiques sur EC2, je vous recommande fortement d'auditer votre stratégie de réservation actuelle. Les ODCR sont souvent méconnues, mais elles répondent à un besoin réel que ni les RI régionales ni les Savings Plans seuls ne couvrent : la garantie de capacité physique.
N'attendez pas votre première erreur ICE pour agir.
Ressources utiles :
- Documentation AWS — EC2 On-Demand Capacity Reservations
- Documentation AWS — EC2 Capacity Manager
- Documentation AWS — Reserved Instances : Régionale vs Zonale
- Documentation AWS — Savings Plans et Reserved Instances
- Blog AWS — Réserver la capacité EC2 avec les ODCR
- Blog AWS — Gérer les ODCR avec Split, Move et Modify
- Blog AWS — EC2 Capacity Manager : surveiller et gérer la capacité depuis une interface unique
- Documentation AWS — Auto Scaling Groups avec Capacity Reservations